简单将博客内容重新整理归档
这样的操作是第几次?忘记了,反正不是第一次,我相信也不会是最后一次。生命在于折腾……
上一次因为用文件夹的形式去存放每一篇笔记,这样子的好处就是每一篇的笔记与之有关的图片、视频、文件都存放在同一个文件夹,方便归纳整理。其实挺合理的,毕竟够直观嘛。但随着时间久了后发现 Hugo 上的content/posts目录越来越重,对于一个才记录了两年多的生活小博客,居然都占了接近百兆的硬盘空间。这让我无法接受,故决定花时间整理一下存档。好了,已经强行找到了理由!
其实这次整理归档主要是想博客里的内容能更好的融合到 Obsidian 里,之前用文件夹归档我将 Markdown 文件都以index.md这样的形式保存的,当查看 Obsidian 的关系图谱时瞬间爆炸,文件名大一统根本无法分辨,黑耀石的灵魂没了,这这这。
重新归档这个事情从使用 Obsidian 开始就提到了计划列表当中,可这份计划列表一拖再拖,半年过去了,终于决定行动起来。当然这当中有一个契机,因为今天我发现在 Obsidian 上可以为 Image auto upload Plugin 这个插件设置一个快捷键实现一键上传文章内所有图片,有了这个功能就可以轻松实现将图片资源转移到图床上了,之前一直不行动起来就是因为不想在每一篇文章里的每一张图片都点右键再选择上传图片。
接下来重新整理文章的标签,清理了前期一大堆乱七八糟的标签,同时也为后期的文章简单添加了对应的标签。因为懒,最近一年多更新的笔记都没有分类与标签的。
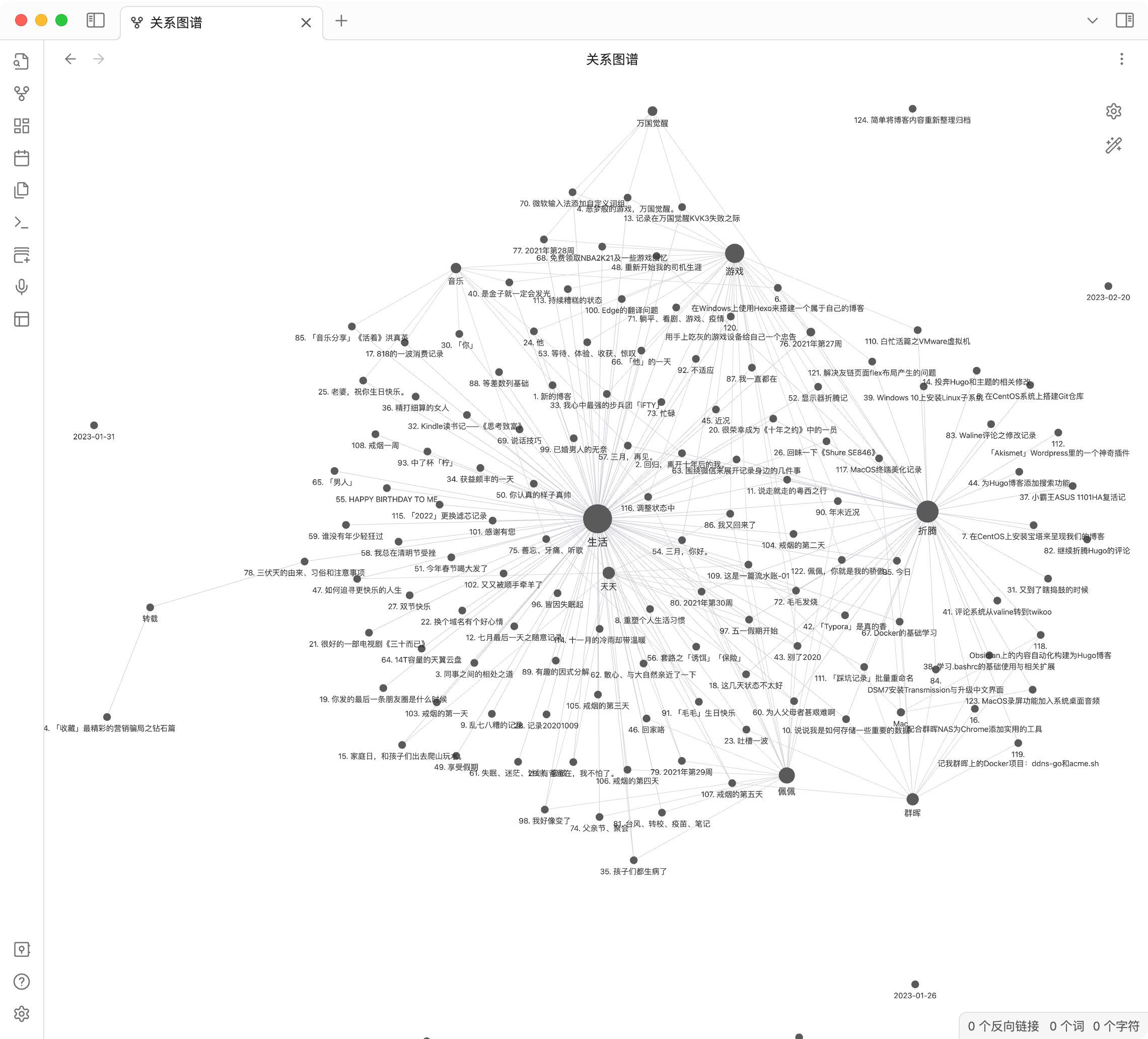
简单处理好后关系图谱的效果也出来了,剩下的就等以后一步步去建设啦。整理时发现了一个问题,就是在 Obsidian 上建立双向链接也属于其灵魂之一,默认的情况下是使用双方括号这种方式去构建双链的,也可以在设置 ☞ 选项 ☞ 文件与链接 ☞ 使用 Wiki 链接 ☞ 关闭即可使用[]()构建双链。个人觉得使用默认是最好的。那么这时问题来了,当在 Obsidian 上更新好内容后,使用 Hugo 生成静态页面时就会因为渲染引擎的关系直接将双方括号以文本的方式渲染到页面里了,简单去了解了一下,Hugo 默认的 Markdown 渲染引擎是 Goldmark,要在这个引擎上面扩展着实不知从何下手,最后选择在自己稍微懂一点点的 JavaScript 上找方法去解决。
const pElements = document.getElementsByTagName('p');
const regex = /\[\[(.*?)\]\]/g;
for (let i = 0; i < pElements.length; i++) {
const elementText = pElements[i].innerHTML;
const newText = elementText.replace(regex, '$1');
pElements[i].innerHTML = newText;
}这里要感谢叶老弟,前段时间和他交谈时了解到 for 循环,学习了一下,没想到这么快就用上了。这种粗暴的解决方法也导致了另外一个问题,~~就是以后文章内的 p 标签里不能使用双方括号了,~~有舍有得,暂时先这样吧。
这两天比较系统地去复习了一遍正则,将之前的正则重新优化了一下,已经解决之前因为粗暴导致的痛点。
const pElements = document.getElementsByTagName('p');
const regex = /([^(<code>)])\[\[(.*?)\]\]/g;
for (let i = 0; i < pElements.length; i++) {
const elementText = pElements[i].innerHTML;
const newText = elementText.replace(regex, '$1$2');
pElements[i].innerHTML = newText;
}最后的最后,祝自己生日快乐。